建好機器學習模型後,大家一定都會關心的議題就是模型好不好,準確率高不高?
如果一個模型的表現不如我們想像中的好,我們可能就要去關心 Bias-Variance Tradeoff ,並想辦法改善這個機器學習模型。
今天要介紹的就是 Ensemble Learing 集成學習,集成學習其實就是讓多個模型去合作,試著去整合多個模型。它可以提升整體性能和準確度,方式可能是從降低偏差( Bias )又或是從降低變異( Variance )去改善模型。
偏差 Bias : 分類器的準確率。使用 training data 訓練出來的模型能不能訰確的預測類別?
變異 Variance : 分類器的精準度。今天如果投入了新資料想進行分類/預測,是否還能準確預測?
高 Bias ,模型太簡單沒抓到所需的重要特徵,容易造成模型 Underfitting。
高 Variance ,模型太複雜了,抓取太多不必要的細節,容易造成模型 Overfitting。
Bias-Variance Tradeoff: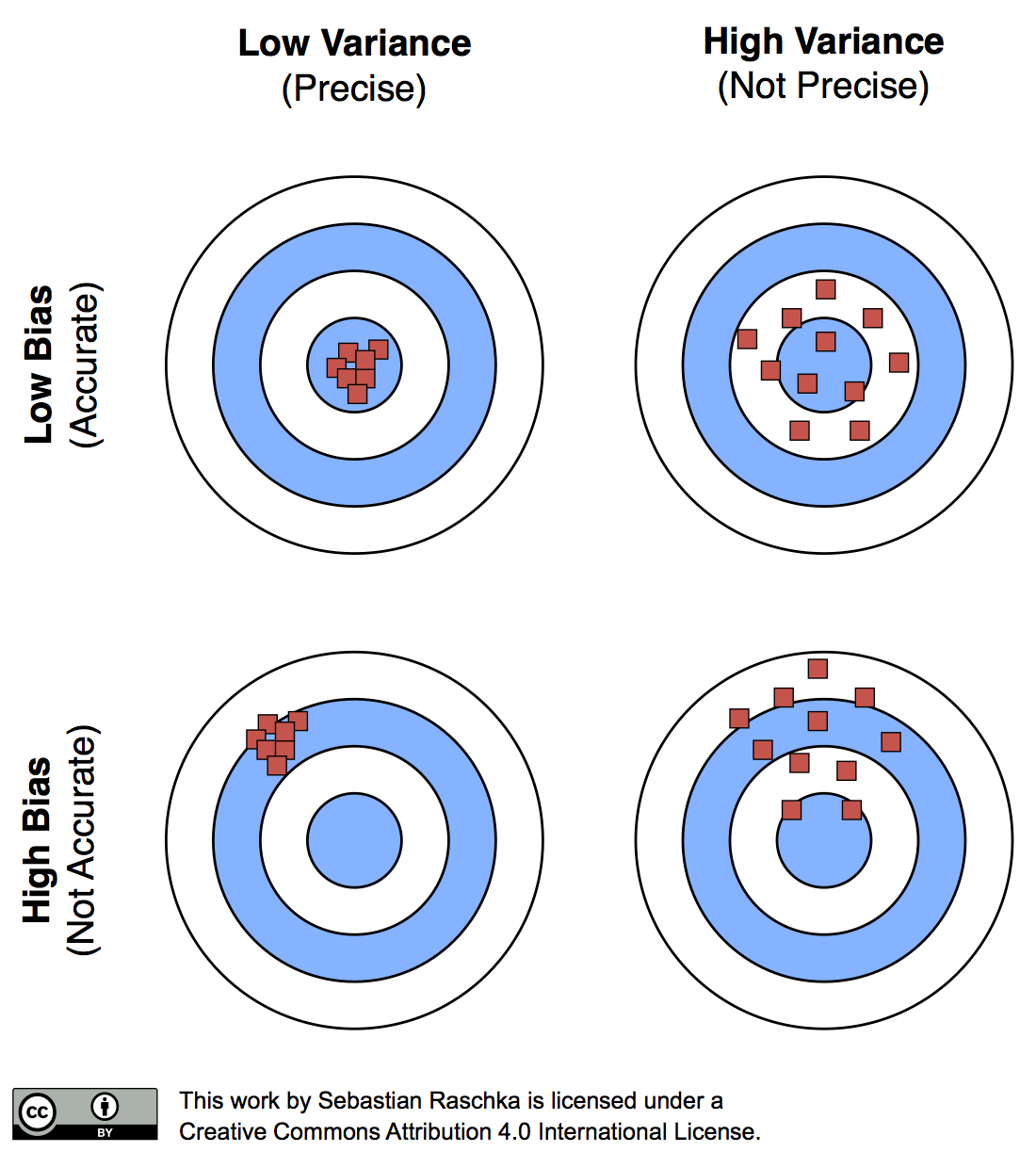
類別型輸出結果(Class Labels Outputs)
投票法 Majority voting
加權投票法 Weighted majority voting
Borda count
連續型輸出結果(Continuous Outputs)
平均 Mean Rule
加權平均 Weighted Average
截尾平均 Trimmed mean (去除極端值後計算的算術平均值)
Generalized Mean
Minimum, Maximum, Median, Product Rule...
常見的集成學習包括這四種:
以下補充他們的演算法架構示意圖、簡單的說明和應用模型:
Bagging 指的是 Bootstrap Aggregating ,方法是取後放回的進行Bootstrap抽樣,得到數個樣本子集,分別對子集建模型在整合結果。
Bagging 模型中。每個子模型的 Bias 都很低,但是個別的variance 較高容易過度擬合,因此把多個模型平均起來降低variance。
Var(Y)= sigma^2 ; Var(Y_bar)= sigma^2/ bag
除此之外,Bagging 模型選擇部分的測試集進行建模,也降低了抽選到極端值的可能性。
Bootstrap抽樣的示意圖: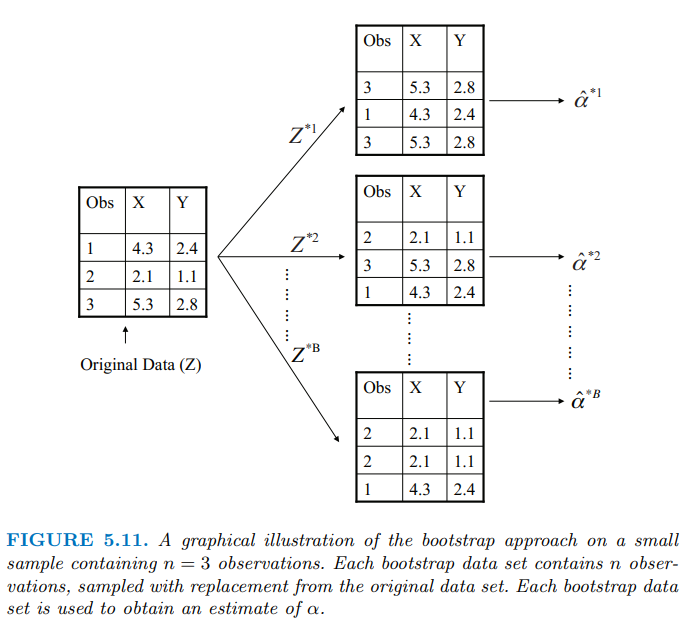
Bagging 演算法示意: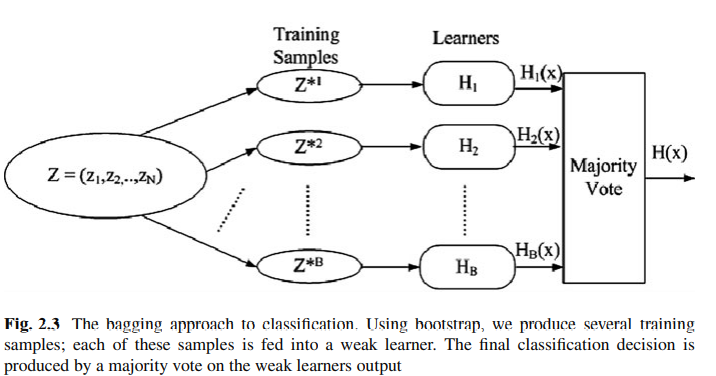
常見的 Bagging 應用包含 Random Forest 隨機森林。
Boosting 被稱為提升法,常被用來降低 Bias 的模型 。
原則上是先去建立一個較弱的模型,給分類錯誤的資料進行加權,再用梯度下降法優化重新建模,重複迭帶下進而降低模型的 Bias。
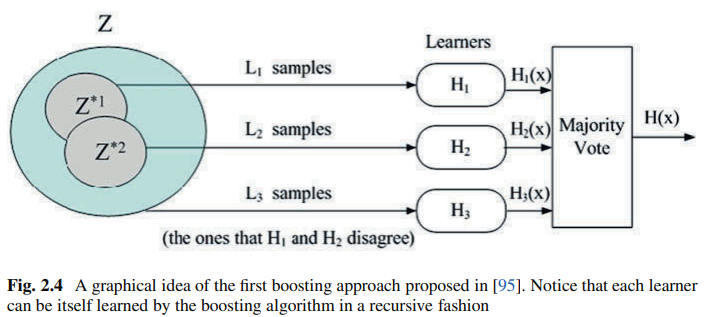
常見的 Boosting 應用包含 AdaBoost 、 LogitBoost, XGBoost, Gradient Boosted Decision Trees (GBDT)。
Stacking 被稱為堆疊法,主要被用來提高模型的預測/分類準確率。
概念是去建立多個獨立的訓練模型,然後再將各預測結果投入 Meta-Classifier (最終的模型)給出預測結果。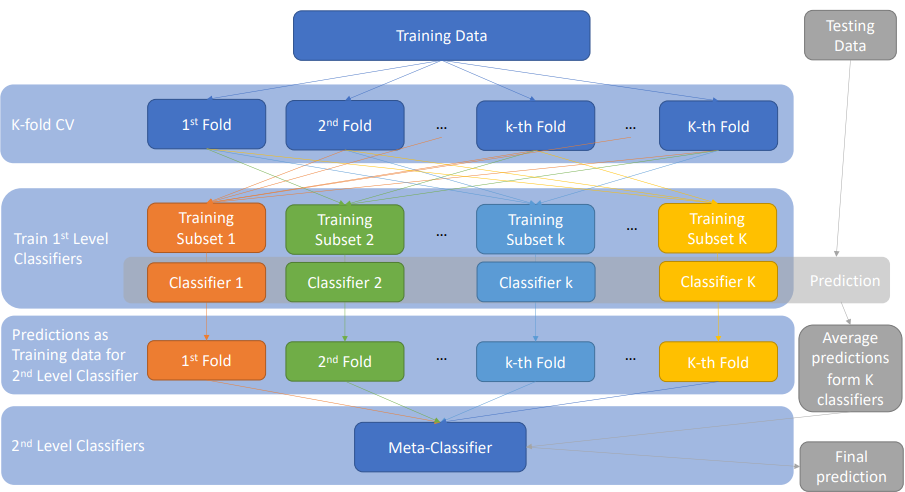
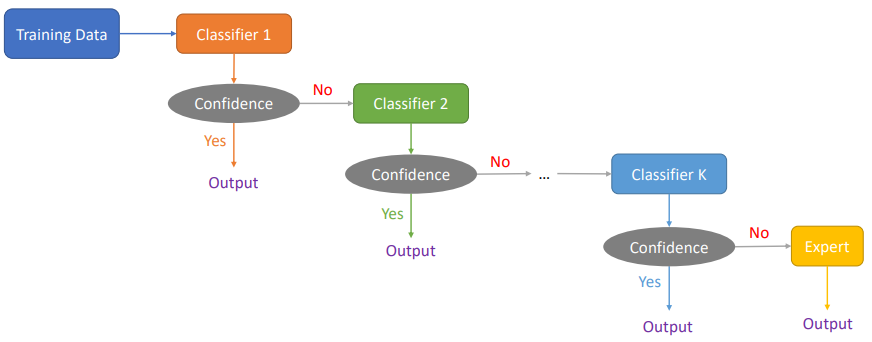
Cascading 又稱為級聯法,這類的集成模型非常非常準確。
級聯法主要用於絕對不能犯錯或是犯錯後成本非常大的情況。模型步驟越後面就建得越複雜,甚至到最後就請專家直接進行人工判斷。
今天先介紹基礎幾個方法的概念,明天打算來補充 AdaBoost、LogitBoost在 R 上的程式碼應用。
模型架構圖來源:
統計與機器學習 Statistical and Machine Learning, 台大課程. 王彥雯 老師.
An Introduction to Statistical Learning with Applications in R. 2nd edition. Springer. James, G., Witten, D., Hastie, T., and Tibshirani, R. (2021).
Ensemble Machine Learning Methods and Applications. Zhang, Cha., and Yunqian. Ma. Edited by Cha Zhang, Yunqian Ma. Boston, MA: Springer US. (2012).
Bias-Variance圖來源:
Model evaluation, model selection, and algorithm selection in machine learning Part II - Bootstrapping and uncertainties by Sebastian Raschka. 2016.
https://sebastianraschka.com/blog/2016/model-evaluation-selection-part2.html
Ensemble Learning — Bagging, Boosting, Stacking and Cascading Classifiers in Machine Learning using SKLEARN and MLEXTEND libraries.(@Saugata Paul)
https://medium.com/@saugata.paul1010/ensemble-learning-bagging-boosting-stacking-and-cascading-classifiers-in-machine-learning-9c66cb271674
R筆記 – (16) Ensemble Learning(集成學習)
https://rpubs.com/skydome20/R-Note16-Ensemble_Learning

